
When preparing to update the GOV.UK search engine, a code change resulted in missing or duplicated search results. Find out how our search team fixed this issue, what we’ve learnt and the safeguards we’ve put in place to prevent it happening again.
Background
GOV.UK search uses the open source search engine Elasticsearch. We customise Elasticsearch using our own API wrapper Rummager. There are multiple publishing applications that feed content into Rummager, which then adds documents to the Elasticsearch index, making them searchable for end users. We wanted to upgrade to a later version of Elasticsearch (2.4) and to do this we had to make Rummager compatible.
What happened
On the 18 May 2017, what should have been a simple code change to Rummager to make it compatible with Elasticsearch 2.4 unexpectedly caused problems for a small percentage of users on GOV.UK.
There were 2 main issues:
- “specialist” pages (like drug safety updates) stopped appearing in finder pages although the pages continued to show up in site-wide search results
- a small number of users also found their search results were being duplicated
The following screenshot shows an example of duplicated results that were returned by searches.

How we responded
The GOV.UK content publishing team flagged the issues within 24 hours so we were able to roll back the 3 line code change before it affected all search results. However, any GOV.UK page updated by content publishers after the code went live would show an issue in the search results. Approximately 3000 pages were updated by content publishers after the faulty code went live. The image below shows the 3 line code change.
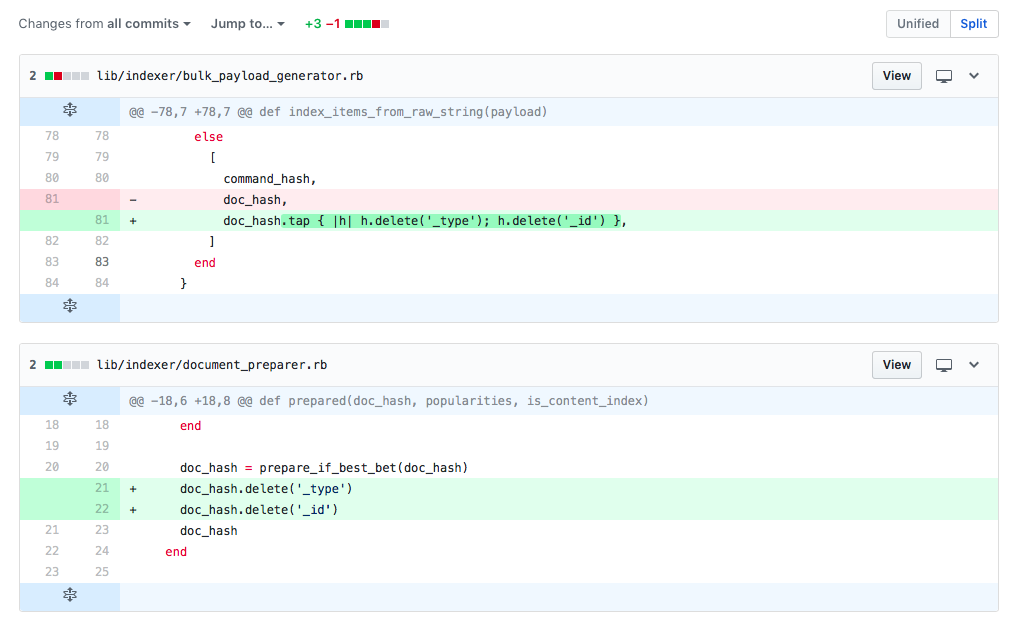
We decided against using our nightly backup to restore GOV.UK to a previous time, because otherwise these content updates from publishers would have been wiped out from search. It would have been harder to repopulate the missing data within search than to correct the corrupt data, because this would have involved resending data from all of the GOV.UK publishing apps to Rummager.
After rolling back the faulty code, our developers fully investigated and fixed the search documents that had been updated while that code was live. During this period of investigation, the quality of search results was affected. Within Rummager, there is a process that modifies the search documents so that frequently visited pages rank higher in search results. During our investigation we disabled this functionality to minimise the risk of making the problem worse.
Why the incident occurred
Elasticsearch identifies documents within a search index using a combination of _id and _type values. In our case, an id is always a URL such as “/driving-licence-fees”, and type depends on the content type of the page, for example (drug_safety_update).
Specialist pages and manuals all have different types, but a lot of pages on GOV.UK use a generic type called “edition”.
When adding documents to the search engine, Rummager used to add the type and id values to the document. This made it convenient to look up the type and id in the same way as other document properties, like the title and description. This meant that whenever we queried Elasticsearch, we’d get a response like this:
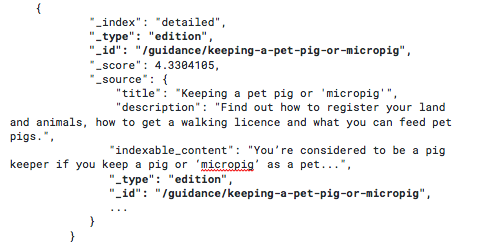
However, we needed our code to remove _type and _id fields from the _source section in Rummager. This was because _id and _type are reserved words in the source section of Elasticsearch 2.4. Our Rummager code change did remove these fields from the source section but there were unintended consequences of this. We hadn’t updated some parts of the Rummager code that depended on those redundant fields, and this is what caused the duplication and missing search errors.
We didn’t catch this during code review, and our automated tests didn’t catch it either. Part of the problem was that documents needed to be indexed twice by Rummager before the problem was visible to users.
Why specialist content disappeared from finder pages
The first time documents were indexed by Rummager after our revised code went live, the “_type” field was copied from the “_source” document to the root-level field (due to an existing quirk of Rummager we weren’t aware of). Then the revised code we’d added deleted the former field.
This Rummager quirk unknown to us meant that the second time a page was indexed, there was no “_type” field in “_source” to copy, so the root level “_type” was set to its default value: “edition”.

GOV.UK finder pages (like the drug safety update page) restrict searches to a particular root level document type, so the pages that changed to edition were automatically excluded from search results.
Why search results were duplicated
After we replaced the faulty code, we republished some specialist documents in order to send Elasticsearch the correct type field again. Unfortunately, this didn’t overwrite the existing documents with the wrong type field, because in Elasticsearch if 2 id-type pairs are different, they are treated as separate documents. This left us with pairs of documents with the same ID, but different types.
To fix the duplicate links, we wrote code that searched for duplicate documents and deleted the ones with generic document type (“edition”). We considered any pairs of documents with the same link or “content ID” (a publishing platform identifier) to be duplicating each other.
Lessons learnt and making sure the incident doesn’t happen again
This incident taught us that you need to understand the core concepts and constraints of your database and always check your assumptions. As discussed in the previous section, we assumed ID was unique for all documents, but it wasn't (different documents could have the same ID but different type fields).
There are multiple steps we are taking to make sure this doesn’t happen again. We have changed the code so that it falls back to “edition” only when it makes sense to do so: when handling input from other applications which do not always supply a “_type”. In other cases, a missing “_type” will cause an error. This fail-fast behaviour would have helped us spot the problem much faster and would have prevented most of the data corruption.
Also soon, when we bulk-load new data into the search index, we will compare the 2 versions (the previous and updated index) using an automated script to check that the only changes are ones which we expect. If fields or documents have been removed unexpectedly the reindexing process will notify us about the error and will not switch to the new version.
We are currently working on changing search indexing to integrate with the new publishing platform. This means there will be a single data source populating the search index, and we will be able to resync the documents if something goes wrong.
Stay up to date with all the latest posts by signing up to alerts from Government Technology blog, join the cross-government conversation on Slack or follow GDS on Twitter

1 comment
Comment by Henrik posted on
Good read.
Another possible source of future bugs in the diff: `Hash#delete` mutates the hash, which could affect other parts of the code that use the same object. If you are on Rails, there is `Hash#except` to return a new modified hash without modifying the current one in place.