
We store all GOV.UK content in 2 databases. When you view a page, the content comes from a MongoDB database. When you search through pages, the results come from an Elasticsearch database.
We were previously using Elasticsearch 2, but that is now old and out of support. However, there were not a lot of GOV.UK developers who knew how to set up and manage Elasticsearch, so it took us some time to build up the knowledge and carry out the upgrade.
We have lots of different databases on GOV.UK and Elasticsearch is very specialised. Upgrading Elasticsearch is not as straightforward as switching the new thing on and the old thing off. It took a little bit longer for us to update to the latest version because there were some gaps in knowledge.
Before we dive into the intricacies of updating Elasticsearch, here’s a little refresher on what happens when you search on GOV.UK.
How search on GOV.UK works
Search powers more than you might expect on GOV.UK. There's the obvious, like the search page and the "finders" like Air Accidents Investigation Branch reports. Our search functionality also fetches the lists of content for organisation pages like HMRC and topic pages like Education, training and skills.
All of these search-powered parts of GOV.UK talk to our Search API application. Search API acts as a middleman between them and Elasticsearch. This is useful because any behavioural changes to Elasticsearch can be handled in one place, in Search API, rather than in everything which uses search.
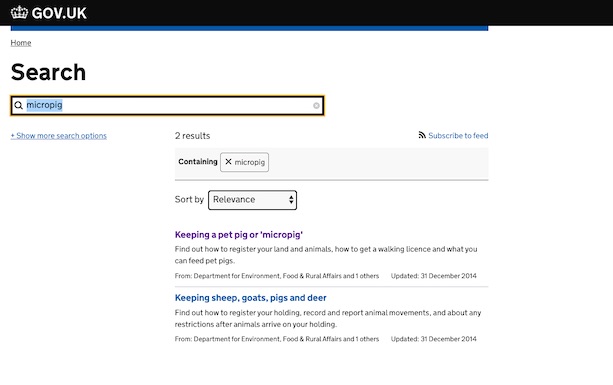
For example, when you search for "micropig", these steps happen:
- Your search query,
"keywords=micropig&order=relevance"is sent to Finder Frontend, the application which powers the search page. The "relevance" part means to sort by descending order of relevance, so the most relevant result will be first. - Finder Frontend constructs a Search API query, which contains your query and some additional details, like which A/B test variant you're in (if an A/B test is active).
- Search API constructs an Elasticsearch query.
- Elasticsearch responds with a list of content matching the query.
- Search API passes the list back to Finder Frontend.
- Finder Frontend displays the results.
This all happens in a second or two and then you have access to all the information you need.
From Elasticsearch 2 to Elasticsearch 5
We spun up a small Search Resilience & Performance team to upgrade to Elasticsearch 5. As a team we spent the first few weeks reading documentation and trying things out locally on our laptops.
We decided to stop managing our own Elasticsearch servers and instead have Amazon Web Services (AWS) do that for us because we knew this would help us in the long term. We still need to know some details about Elasticsearch, but far fewer.
We can always go back to managing Elasticsearch ourselves in the future if we need to because it’s open source software, meaning the switching cost is low. Using and contributing to open source software, where appropriate, is one of GOV.UK’s principles.
We migrated from Elasticsearch 2 to Elasticsearch 5 by switching one application over at a time. This process took 3 months. We set up the new Elasticsearch in AWS, ran a second instance of Search API, and made all the publishing applications send their content to both. We then changed which instance of Search API other parts of GOV.UK used to answer queries over the course of a couple of days, keeping an eye on our metrics to make sure we did not break anything.
There was no A/B testing, we did not serve some users results from Elasticsearch 2 and some from Elasticsearch 5 simultaneously. But we compared the results for the top 5,000 search queries over the past few months, looked for any queries which seemed significantly worse, and made changes to how we queried Elasticsearch 5 to fix the problems we noticed.
Onwards to Elasticsearch 6
When we started to plan the migration to Elasticsearch 6, we decided that we wanted to do it slightly differently. We decided that, rather than run 2 instances of Search API, we would just have the one, which would talk to both Elasticsearch 5 and 6.
Having 2 Search APIs running was necessary for the switch from Elasticsearch version 2 to version 5, but caused some headaches. This is something we did not want to repeat when upgrading to Elasticsearch 6. We also decided to use an A/B test to control which Elasticsearch answers a query, so we could more easily compare the two.
Elasticsearch 6 introduced some significant changes to how relevancy was calculated, so the results for some queries were wildly different. A/B testing turned out to be critical, and helped us decide when the results were good enough to fully switch over, and turn Elasticsearch 5 off.
Testing that the new search was good enough
We did not just hope for the best and switch to the newer Elasticsearch. We did some comparison of the 2 versions. Both upgrades involved making tweaks to the new Elasticsearch. There were 2 main things we looked at.
1. Popular queries
The simplest analysis we did was to fetch the top 10 results for selection of recently popular queries, and look at cases where they differed. For the Elasticsearch 5 upgrade we looked at the top 5,000 queries over the last three months, for the Elasticsearch 6 upgrade we looked at the top 10,000.
There were a lot of changes. But most of them were cases where the 10th-place result had changed, or something else minor like that.
2. User behaviour
We record a lot of data about how people use GOV.UK through Google Analytics. The 3 metrics we check to see if search is performing well are:
- click-through rate: how frequently people click on a search result
- refinement rate: how frequently people adjust their search query after seeing the results
- exit rate: how frequently people leave GOV.UK entirely from the results page without clicking on anything
Our assumptions are that a higher click-through rate means that people are finding content that looks relevant to their query, and so is good. High refinement and exit rates are bad as they mean that people are not finding the results they want.
A/B testing
With the Elasticsearch 6 upgrade, we served some user queries from Elasticsearch 5 and some from Elasticsearch 6. This let us look at the how the user behaviour differed for each, and so decide if the new Elasticsearch was performing well enough.
When we first tried this, not only did we see Elasticsearch 6 performing significantly worse in the metrics, we even received a couple of support tickets about strange search results! For example, a search for "theresa may" gave Tax your vehicle as the top result, as it's popular and has the word "may" in the page text.
It turns out the changes to ‘relevancy’ in Elasticsearch 6 had a bigger impact than we expected, and we had to do some more work to handle that. We then ran the A/B test again, and found that Elasticsearch 6 on-par with the previous version. We decided that we could live with things being a little worse, as after the upgrade we planned to start work on improving search performance anyway.
Next steps for search on GOV.UK
Our next step is to investigate some more user-visible features like spelling suggestions and auto-complete to improve the experience and change users’ behaviour.
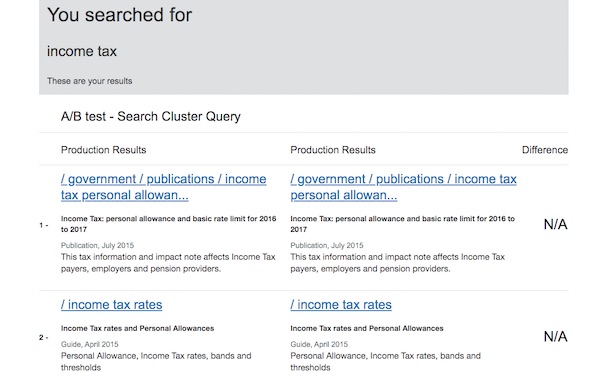
We suspect that a lot of people do not find what they're looking for on GOV.UK because they search for general terms like "tax". By making auto-complete suggestions as the user enters their query, we can encourage them to search for more specific phrases, like "income tax".
We’ll also need to upgrade to Elasticsearch 7 at some point, but not for a while. When that happens we expect to tackle some big issues, like the relevancy changes in Elasticsearch 6, but we'll have the experience of 2 upgrades behind us to ease the journey.

5 comments
Comment by Tim Wisniewski posted on
Nice write up. Great idea making the new Search API support two backends to make future upgrades easier. I bet your future selves will thank you!
Comment by Anthony Williams posted on
Agree
Comment by Jack Spree posted on
There are some fundamental problems with GOV.UK search that need addressing.
For example, searching for "EHIC card":
https://www.gov.uk/search/all?keywords=ehic+card&order=relevance
It's obvious that we are not looking for a passport, yet that is the first two results.
"Disability" brings up "Tax your vehicle"
"cabinet" brings up reams of "cabinet office" results with not sign of the cabinet of ministers that that department supports.
I understand you give an artificial boost in relevancy scores for key pages, like passport renewal, paying vehicle tax and universal credit. I can see you did this as a simple fix so that, for example the passport renewal page comes above the dozens of less important passport pages. But these key pages attract searches for other topics too, just because they share a word.
At the root of this is performance metrics. I'm rather stumped that GOV.UK relies on the really basic default analytics such as whole-page click-through vs exit rate, rather than search metrics that are well-understood. For common queries you should look at two things for some representative queries:
1. Click-through-rate of each search result should decrease as you go down the page. If the third result is most popular then it should probably be moved up.
2. Compare search results (relevancy scores) with human-curated scores. Google publishes its extensive relevancy scoring criteria. You can create a bank of these and create a dashboard to track this over time, and add new search terms and pages as they become flagged as tricky.
This would give you a better framework to guide improvements, for example as you tune your ElasticSearch parameters as you outline in this blog post. But more importantly it will reward innovative improvements, such as your list of domain-specific synonyms, abbreviations and possible future work on semantic relationships, topic graphs and other NLP.
Comment by Michael Walker posted on
Hi Jack,
Those are good points, and our current Elasticsearch ranking definitely has problems. Popularity boosting was added to fix some problems... but it makes "universal credit" (and other super-popular pages) show up near the top for almost every search, which is bad.
So we've been looking to metrics like nDCG to guide improvements to our ranking, and recently built a tool for publishers in government to easily give us relevancy judgements for queries important to them. We also monitor queries which have undesirable click-through rate patterns like you mentioned, where the top result is not what people want.
One of the possibilities we've been trialling is a machine learning model for ranking search results. This would be trained using per-query data, like the Elasticsearch score for different fields, per-query click-through rates, and manual relevancy judgements. So far it's been very promising, rather beating all the manual tweaks we tried to the Elasticsearch query. There are some boring issues to iron out before we can switch to it in production, like monitoring and alerting, but rest assured we know result ordering could be better, and we're working on it.
If you'd like to read more on our machine learning work, we have some high-level documentation here: https://github.com/alphagov/search-api/blob/master/doc/arch/adr-010-learn-to-rank.md
Comment by Richard Smith posted on
I've just been working on upgrading the ONS Address Matching API to Elasticsearch 7.3.
ES7 uses Lucene 8 under the hood and this gives significant performance and functionality improvements. However, the change did cause us a fair bit of work due to the removal of the classic TF-IDF similarity module in favour of BM25. The latter is superior but our complex queries were so heavily tuned the results were initially worse. For comparative purposes, we use a series of baseline tests which provide a real-world simulation of all the different types and formats of addresses to be matched. Using these tests in a grid search on sub-query boosts and the index settings "b" and "k1" eventually gave us better results overall.
Also, from ES 7.1 onwards the security features are included with the free version.