The GOV.UK Platform as a Service (PaaS) team recently held our first light-touch incident response and recovery workshop. We wanted to find a way to practice tackling different sorts of platform incidents that was quick to set up and prepare for. We designed it to help everyone in our team consider what they would do when faced with a critical problem, so they would feel more confident investigating and resolving incidents.
Context
A large number of services rely on GOV.UK PaaS for hosting their applications. These services often need to be available 24 hours a day, 365 days a year. However, sometimes things can go wrong, be it a machine failing, an upgrade having a bug or a fire in a data centre. Some of these are fairly routine and it’s our job to make sure the platform is resilient enough to withstand them; others are less common.
We like to keep ourselves ready for all of these situations and more. One way to do this is to hold game days - think military practice, using allies as mock adversaries, rather than Cluedo.
We have held game days before, where engineers complete tasks on clones of our production environment, but the technical preparations often take several days to set up, and completing the exercise usually takes a full day for all our engineers. This meant we could only run game days infrequently and when we did run them, engineers just practiced working on more general failure modes. These also occurred when we were physically in the office.
One thing the team really wanted was to find easier, quicker ways to rehearse incident response and recovery practices so that these could be done on a more regular basis, when we were operating remotely and as part of training to join the support rota.
What we planned
To plan our incident rehearsal sessions, Lee, our Technical Lead, thought about the ways in which GOV.UK PaaS could go wrong. He also considered how to fix each scenario, and what the impact would be for both our end users and our tenants. (We refer to people who use services hosted on GOV.UK PaaS as ‘end users’, and people who own those services or apps are called ‘tenants’). Understanding the impact meant we could prioritise scenarios to practice as a team.
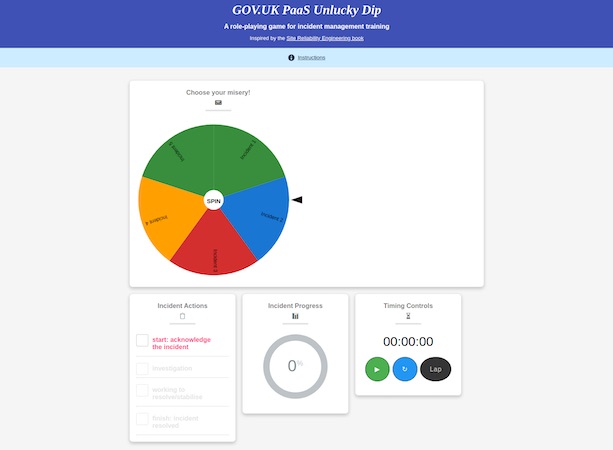
We took the scenarios Lee discovered and documented and ran a role play incident workshop to practice our response to them. This approach took influence from the Google SRE Wheel of Misfortune approach, which is similar to a role-playing game scenario, but with fewer dice and a big wheel of problems!
We chose to run ours as a team-based exercise, as this more closely reflects how we work on GOV.UK PaaS. To prepare for running the workshop, we based ours on Google’s Wheel of Misfortune and added in our own scenario triggers, thanks to open-source working. We also turned our scenarios into a script, ready with scenario context and clues to help our team investigate each scenario problem.
How the session worked
One team member volunteered to spin the Wheel of Misfortune. Once it stopped our scenario triggered and we started our stopwatch. Lee and Jenny, our Delivery Manager, set the scene:
It was a cold, rainy evening when you were tucked up in bed, fast asleep when --RING RING! RING RING! You turn to look at your phone and it’s the number you never want to see: Pagerduty is calling you. You’re given the message that there have been 3 smoke test failures in a row.
The team started an investigation stage, and we used a template to guide and record our thoughts. For example, we asked ‘What do you do first?’, ‘Is there anything you’d check?’, and ‘What would you expect to find?’ At this early stage we didn’t expect anyone to have the answers, but we were looking at how they would start investigating the issue.
Then our comms leads entered the scenario. To make it as realistic as possible they were tasked with supporting our engineers, helping to identify the severity of the incident and to update our tenants. We guided our team comms leads by prompting them with questions: ‘What is the expected impact to end users and tenants?’ and ‘What are the key points in your email to tenants?’
The team asked more questions, where Lee’s input was crucial. He helped steer the team and keep the incident scenario on track. Our team continued their investigation, identified the cause and then worked together to decide the steps they would take to resolve.
What we learned
With the incident successfully resolved we had some time to reflect on how the session went. This helped us identify any actions we needed to take to improve our incident response process. The team found it a useful simulation of an incident and it gave the whole team a chance to talk about crucial decisions that would usually have to be made under the pressure of an incident. It also taught the team about new and unfamiliar failure modes.
It’s hard to have every eventuality mapped out for facilitators to answer, so you do need to have someone on the facilitating team that knows the service well from a technical point and can guide the team in the right direction, or help if they get stuck.
We found asking a team member to note-take helped - we have a record of our conversations and the reasoning behind decisions. This will be a useful record to look back on.
How rehearsing incidents could help your team
Our incident workshop might be useful for your team if you need a way to practise your incident drills without having the overhead of creating a full simulation environment. The first session takes a little time to prepare, but then you can run exercises more frequently and add to your test scenarios over time.
It’s also a really great way of introducing new engineers to platform support, as there is a lot to learn about incident investigation and how systems connect together.
We’ve already planned our next few incident scenario workshops, and we’re making incident rehearsal a regular part of our team cadence. So the people in the GOV.UK PaaS team will be taking their chances and spinning the Wheel of Misfortune for a while longer…
If you’re interested in running your own incident rehearsal session, you can find the resources we used here:
