GOV.UK has a strong culture of testing the changes we make to our apps. We often write tests before we make a change (as in test-driven development), and all the existing tests need to pass before a change can be deployed (as in regression testing).
Sometimes it’s more practical to test a change manually, and over the years the idea of doing some kind of manual check had become a staple in our deployment process. But having too many manual checks can lead to problems. For example:
- it’s hard to know what checks need to be done when we make future changes - in the worst case, the knowledge of what checks to do may be lost entirely
- the balance of automated tests and manual checks can vary significantly, as each developer could make their own choices - this paints a confusing picture
As GOV.UK continues to develop, it would be easy to lose sight of the gaps manual checks were meant to fill. Replacing them with automated tests is not straightforward, as over the years the types of tests we write have evolved, and while each type has its merits, it’s hard to tell which ones we should continue to invest in.
This is an exciting challenge for GOV.UK, as we prepare to deliver more at scale. More code means more tests, so now more than ever we need to agree what good looks like. Agreeing when we have enough tests is also critical for switching our apps to Continuous Deployment. This blog post is about what we’ve agreed so far.
What’s in a test?
GOV.UK is an ecosystem of 70 applications and components, which are mostly written in Ruby on Rails. For each app, we have tests to make sure it works in isolation:
- unit, integration and UI tests - these test the behaviour of the app and rely on simulated communication with other apps and services
- visual regression tests - these run against rendered HTML to verify it appears as expected (most of our apps use components instead of raw HTML)
- runtime health checks - many of our apps have a way to give a live report of their internal status, such as connectivity to a database
Apps also need to work together to provide GOV.UK as a whole. So as well as testing them individually, we also have tests that span multiple apps:
- contract ('pact') tests - these test an API and its consumer with a set of pre-recorded requests and responses (GOV.UK Pay already uses them extensively)
- end-to-end (E2E) tests - these run across multiple apps in a Docker environment, with the aim of testing complete journeys for government publishers
- smoke tests - these run directly against the GOV.UK Integration, Staging and Production environments and test the public-facing parts of the site
Not every app had every type of test. For example, only one app had contract tests, and some apps had no unit tests for their JavaScript code. It was hard to tell at a glance if these were genuine gaps or if that type of test was redundant here. To make progress, we needed to agree what the tests for a typical GOV.UK app should look like.
A new standard
We can always write more tests, but the number of possible faults is infinite, so we need to find a balance. People often refer to the test pyramid as a guide for writing new tests, but while this can help channel our efforts, it’s too vague to use as an auditing tool. We needed something quantifiable and specific to the way GOV.UK is structured.
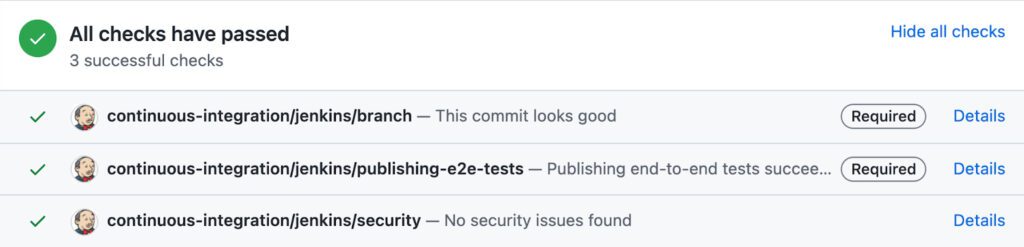
One way to think about the problem is to borrow a concept from security: an 'attack surface'. Instead of attacks by humans, we can think of attacks by 'bugs', where the role of tests is to defend certain parts of the code. So rather than seeing GOV.UK as one big mass with a test pyramid on top, we can break it down into a surface of possible bugs.
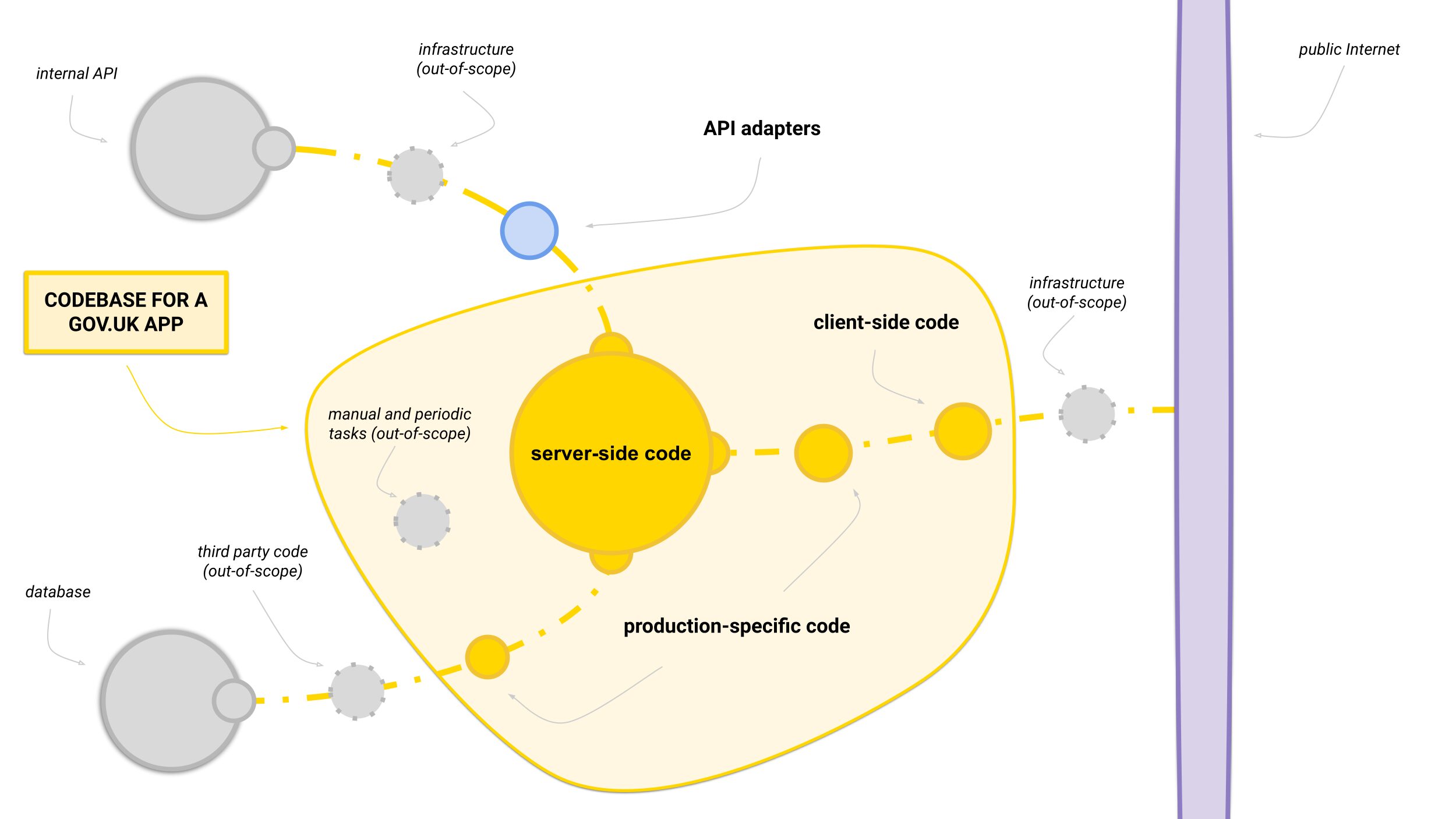
Each area on the bug surface needs a different type of test to protect it. As part of switching our apps to Continuous Deployment, we agreed on what a safe minimum should be for each type, and the result was a new standard of testing:
| Area of bug surface | Strategy for testing |
| Server-side code | Server-side code should be at least 95% covered by unit, integration and UI tests. Most of our apps were near this already. Since it’s a one-off target for enabling CD, we can treat it as an opportunity to think deeply about any tests we’re missing. |
| API adapters | APIs and their adapters must have at least one contract test if the API is used by multiple “consumer” apps, as multiple consumers are more likely to get out-of-sync. Asking for one test should be enough of a prompt to write more. |
| Client-side code | Client-side code is mostly small amounts of JavaScript. We found there were two extremes: some apps had thorough tests and others had none at all. We require at least one JavaScript test, as a simple prompt to fill the void. |
| Production-specific code | Production-specific code includes startup code, as well as config for production infrastructure, like a database. Each app should have a deployment health check to prove it’s running and probe each service it uses to read and write data. |
| Manual and periodic tasks | Out-of-scope. These tasks are naturally non-critical, so the impact of a bug doesn’t change significantly by switching to automatic deployments. We can always choose to write more tests for them if we feel the need. |
At first sight this might look too vague to be useful, but actually the opposite is true. Instead of trying to specify the individual tests we need to have, this standard guides us to places where there might be gaps. Instead of an overbearing list of requirements, it’s a set of simple prompts that builds on our existing culture of testing.
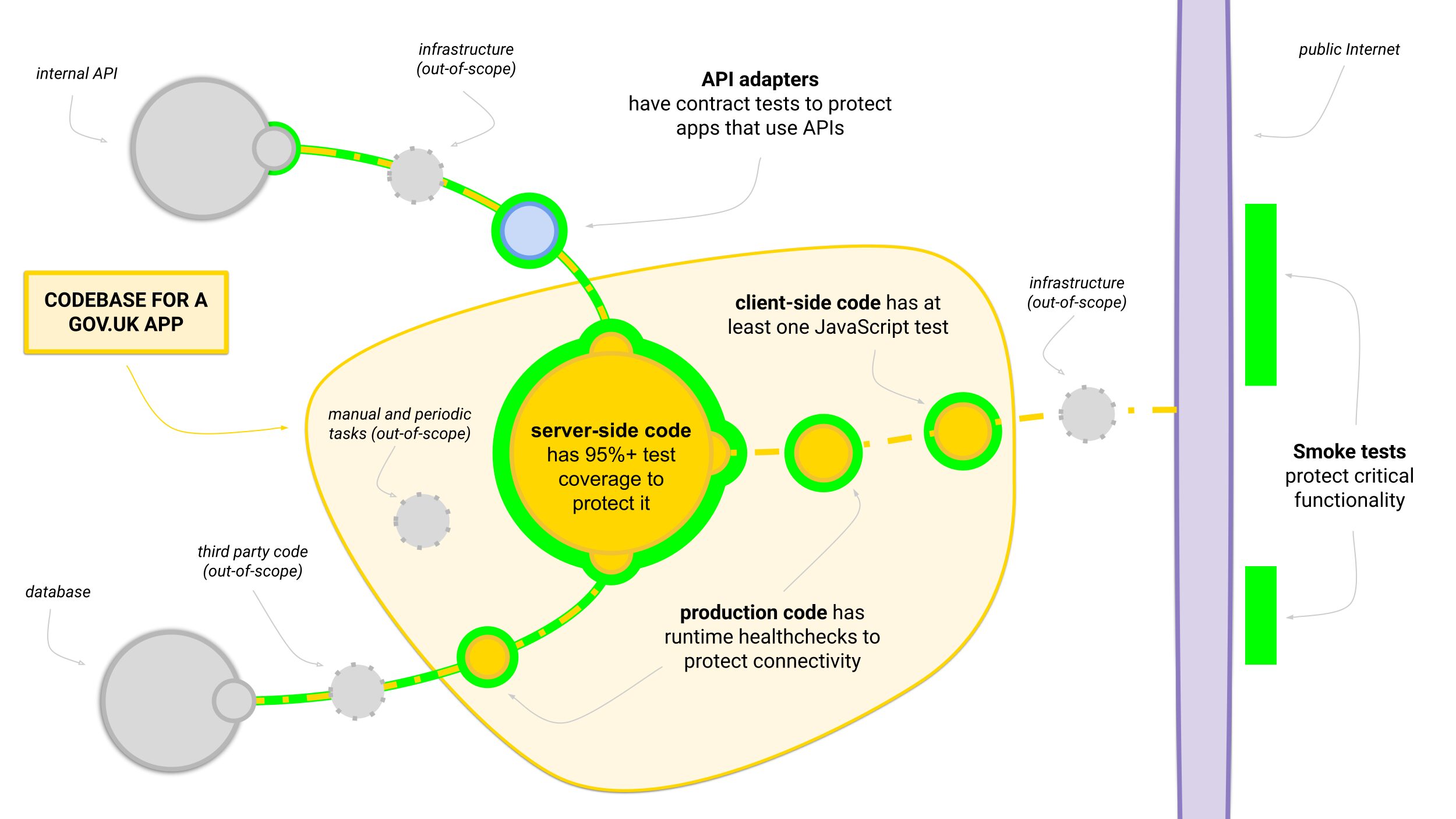
A problem we had when writing the new standard was deciding what to do with the Smoke tests and the end-to-end (E2E) tests. The E2E tests in particular were extremely slow and temperamental, so we were reluctant to add more of them.
Smoke tests are really an extra layer of tests for 'critical functionality'. Given the secondary nature of the tests, we agreed that for now it’s out-of-scope to decide what 'critical' means exactly. For now, we assume all our existing Smoke tests represent critical functionality, that’s worth checking twice.
E2E tests can be seen in the same way. Unfortunately, the ones we have are brittle and slow, to the point where we often disable them temporarily when they block time-critical changes. We agreed that, in their current form, we would get more value from deleting the E2E tests than trying to maintain them.
We audited every GOV.UK app against the new standard. Some apps had more issues than others, usually due to their size and complexity. Some of the issues would be trivial to fix, while others would need more investigation. To really understand the effect of the standard on GOV.UK, we would have to start applying it.
Case Study: Whitehall
Whitehall (GOV.UK’s oldest app) has had many responsibilities during its lifetime - at one point, it was GOV.UK. Bringing it up to scratch presented a number of challenges when we implemented the new testing standard.

First, we needed to assess Whitehall's test coverage. This involved a manual audit, aided by a test coverage tool: SimpleCov which reported 89%. We found that a portion of the 'missing' tests related to code that was no longer used. In order to obtain a realistic percentage, we had to remove this code.
The audit highlighted to us the areas most in need of improvement, and from this we added integration tests, which make sure the various components used to form a page work together successfully. We also added unit tests for important classes (helpers, models, and more). We didn’t add tests where the amount of logic was minimal, for example: configuration classes. We then ran the coverage report again which returned 95.5% (a higher percentage than the target).
Tests for manually triggered rake tasks were not in scope, but we added them for certain tasks that we deemed 'high value'. These tasks are often used for maintenance purposes, like bulk updating live pages and so it's important they work as expected, which the tests ensure. The added tests brought the coverage up to 96.7%.
As well as being a frontend and publishing tool, Whitehall also provides some API endpoints, such as gov.uk/api/world-locations. As these APIs are used by multiple 'consumer' apps they require contract (Pact) tests. GOV.UK uses a Ruby gem, GDS API Adapters, as a middleware for app to app communication. Instead of adding tests in every consumer app, we added them between GDS API Adapters (for the consumers) and Whitehall (the provider).
Finally, we added extra health checks to make sure Whitehall could successfully talk to all the services it depends on. There were already a couple of health checks that had been implemented, one for Redis and one for MySQL. The additional health checks tested connectivity for Memcached and AWS S3.
What’s next?
We intend to apply the standard to all our apps, and at the time of publication we've already standardised over 60% of them. Once we have implemented the new testing standard in enough of our apps, we can then look at removing the old end-to-end (E2E) tests. Running these has a significant development cost and the limited protection provided by them will be negated by the other improvements in testing from implementing the standard.
This is just the beginning. We need to think about how we can make the standard part of the day-to-day work of developers, for a GOV.UK that continues to evolve. We need to challenge what we agreed and if we should ask for more. This means digging deeper into the types of tests we write, and agreeing tools and processes we can put in place to monitor gaps. What does a practical E2E test look like? Is it fair to enforce code coverage?
Look out for more blog posts on this.
