When I started working on vCloud Tools, we had most of our functionality in one repository. There wasn’t a clear separation of concerns – the code was tightly coupled – and it also meant that a user who only wanted to use one tool to do one job had to install the whole thing. So I pulled out each functional area into an individual Ruby gem.
Rewriting history
When creating the repository for each new gem, I didn't want to lose all the commit history; it is very useful documentation. If I had started each gem from scratch, the commit history would remain in the vcloud-tools repository, but I prefer not to have to go somewhere else to see the history of what I'm working on right now.
I also didn't want to create each directory side-by-side and then delete the unnecessary code, as this would make each repository much larger than it needed to be (as Git stores all the history) and would essentially be several duplicated projects with different bits deleted.
What I really wanted was to go back in time and to have started with this structure from the beginning.
Luckily, Git provides a mechanism to do this: git filter-branch.
Creating the new repository
To get started, I cloned the existing vcloud-tools repository locally:
git clone --no-hardlinks /path/to/vcloud-tools-repo newrepoYou need the --no-hardlinks flag because when cloning from a repo on a local machine, files under .git/objects/ are linked to the original to save space, but I wanted my new repo to be an independent copy.
I then deleted the remote in newrepo. I didn't want to push my new, pared-down repo over vcloud-tools.
git remote rm originDeleting irrelevant code
Having made a new repository, I then pruned away any code that was unrelated to that tool. So for example when pulling out vCloud Core, I pruned away all directories that didn't contain vCloud Core code.
For this, I used a tree-filter. This checks out each commit and runs a shell command against it, in this case rm -rf c, where c is an irrelevant directory or file.
git filter-branch --tree-filter "rm -rf c" --prune-empty HEADBecause it's checking out each commit, it takes some time to do it this way (though it speeds up, as using --prune-empty removes commits that are left blank after the shell command does its job, so the total number of commits decreases as you progress through the task).
This command actually allows you to use any shell command you want, but I found that deleting things I didn't require one-by-one, while time-consuming, meant that I picked up some things that had been missed, for example files in the wrong place and tidy-up that needed to be done.
Tidying up
After each time you run this command and prune away files or directories, you need to do some cleanup. (I just wrote a little shell script and ran it each time.)
When you run git filter-branch a .git/refs/original directory is created, to allow for a restore. These objects will be retained if you don't remove them so you need to remove the references:
git for-each-ref --format="%(refname)" refs/original/ | xargs -n 1 git update-ref -dThese are usually cleaned up by Git on a scheduled basis, but because I was going on to remove other folders, I wanted to expire them immediately, and then reset to HEAD in case that had changed anything.
git reflog expire --expire=now --all
git reset --hardThen, I forced garbage collection of all orphaned entities.
git gc --aggressive --prune=nowThe final line of my shell script just output the size of the .git folder so I could see it getting smaller as I pruned away unneeded code.
du -sh .gitImportant warning!
You need to be extremely careful when rewriting history. It is very important not to do this on a public repository unless you have a very good reason, as it makes everyone else’s copy of that repository incorrect. So I waited until it was finished and I was happy with my local version before pushing it up to a new repository.
Applying gem structure
For all tools other than vCloud Core, the first thing I had to do was redo the directory structure.
I also had to move the file that loads the dependencies, and during the pruning process is became clear that we had a lot of dependencies at the wrong level, or not required at all. Deleting code is very satisfying!
I then added the required files for a gem, for example a gemspec, a licence. At this point, I also added a CHANGELOG to help us move the tools to open source.
Some interesting things about Git
I discovered some new things. For example, Git is case-insensitive with regard to file names.
git mv spec/vcloud/fog/Service_interface_spec.rb spec/vcloud/fog/service_interface_spec.rbtold me:
fatal: destination exists, source=spec/vcloud/fog/Service_interface_spec.rb, destination=spec/vcloud/fog/service_interface_spec.rbYou need to force it with the -f flag.
Also, you can copy commits from another repository, as if you were using git cherry-pick to copy from a branch in the same repository, by creating a patch and applying it locally.
git --git-dir=../some_other_repo/.git \
format-patch -k -1 --stdout | \
git am -3 -kThen I published the gem
To enable our continuous integration, I added a Jenkins job and a Jenkins hook to GitHub so that a commit to master will trigger a build in Jenkins.
Once I was happy that everything was present and correct and it was ready to publish, I added a gem_publisher rake task, and then included that in Jenkins. This means that when a commit is merged to master, if the tests pass and the version has changed, the new version is automatically published to RubyGems.
Ta-dah! vCloud Core.
Finally, I made a pull request on vCloud Tools to remove it.
Pulling out all gems
Over a couple of months I pulled out all the gems and the architecture of vCloud Tools now looks like this:
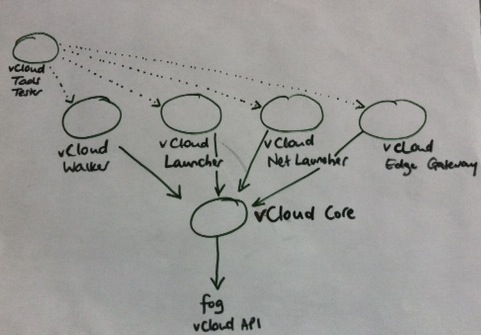
This approach follows the UNIX philosophy of simple tools that do one thing, which together can form a toolchain to do do more complex tasks. vCloud Core now takes care of the interactions with fog and the vCloud API, and the other tools depend on that. vCloud Tools is now a meta-gem that pulls in all the other gems as dependencies. This has definitely made it easier to develop on and use vCloud Tools, and I learned a lot about Git and Ruby gems along the way!
If work like this appeals to you, take a look at Working for GDS - we're usually in search of talented people to come and join the team.
You can follow Anna on Twitter, sign up now for email updates from this blog or subscribe to the feed.

6 comments
Comment by Roberto Tyley posted on
Great post! As the author of The BFG (an alternative tool to git-filter-branch for removing unwanted Git history), I just wanted to remark that the slowness you experienced with git-filter-branch is an area where The BFG typically does a lot better- usually between 10-500x faster. Here's a short video showing a speed comparison:
https://www.youtube.com/watch?v=Ir4IHzPhJuI
Incidentally, regarding Git's case-sensitivity, I think that the behaviour you saw depends on what kind of filesystem you're on - for instance, Mac OS X's filesystem 'HFS+' is case-insensitive (tho confusingly, also 'case preserving') - so if you have a file named 'Service_interface_spec.rb', then 'service_interface_spec.rb' effectively already exists - so the move is rejected. If you execute the same command on Linux- which IS case-sensitive - the move will be successfully applied.
Internally, the Git model represents filenames as pure-byte representations, staying agnostic about the whole encoding business -so typically behaves in a case-sensitive way.
Comment by Anna Shipman posted on
Thanks for this, Roberto. And good point about the file system, that makes perfect sense – I hadn't made that connection. Thanks for the clarification!
Comment by Matthew Somerville posted on
Even without using a nice third-party tool, you can speed up filter-branch a lot by using an index filter rather than a tree filter. If you're simply removing files, there's no need to actually check them out, you can just purge them from the index, and the outcome should be the same:
git filter-branch --index-filter 'git rm --cached --ignore-unmatch filename' HEAD
Also, the --force argument to filter-branch lets you run it again without removing refs/original/, if you'd prefer just to do multiple removals and then clean up at the end 🙂
Comment by Anna Shipman posted on
Great tips! Thank you, Matthew!
Comment by Will Benyon posted on
It's worth noting that purging history in the new repositories may lose useful history of content that, while relevant to the component, originated in a file that currently isn't.
Say, for instance, some functionality grew as a feature in vcloud-walker files, before being moved to a vcloud-core file. If the new vcloud-core repo is purged of any vcloud-walker file history, git will simply show the file as being created at the point the content was moved into a vcloud-core file. If the history were kept in full, it would be possible to track even the earliest revisions of the feature (when it was part of vcloud-walker).
This is particularly useful for git commands that will detect moved or copied lines across files. For example, git blame with the -C option will attribute line changes to the person who edited the line, rather than someone who moved the function.
Comment by Anna Shipman posted on
Thanks Will! That's a useful point, and something to be considered when deciding whether this approach is right for you. It's definitely better if you can get the architecture correct from the beginning 😉