Over the past 18 months or so we've devoted a lot of effort to the programme of migrating our confusing mix of publishing mechanisms to a new, more efficient centralised architecture.
We've written a fair amount already about the progress of the migration and some parts of the functionality of the new platform but we've never really described what the whole system looks like. Having recently taken some time to write a long-term vision for the platform I wanted to explain its components in more detail here.
What we’re building and why
Firstly it's worth revisiting what we're doing and the reasons behind it. The publishing platform is the core of the migration programme, which intends to make GOV.UK's technical architecture simpler. The architecture will be easier for development teams to understand when diagnosing and fixing problems, quicker for new developers to grasp, more reliable, and less work to maintain and build on.
The publishing platform will offer a single method for publishing content from all of our applications including Whitehall Publisher, Specialist Publisher and Travel Advice Publisher. The platform will be responsible for all aspects of content publishing so that we write functionality once and use it everywhere, rather than re-implementing the same things in different applications.
The main responsibility of the publishing platform is to be the canonical store of content for GOV.UK: not only the items currently visible on the site, but also those currently in a draft state before publication, or those that have been superseded or removed from the site for other reasons.
The platform and its apps
The platform is just one element of the entire publishing architecture; outside it at one end are the publishing apps (eg Whitehall Publisher) that are responsible for providing the editing interface for publishing users. At the other end are the frontend apps (such as government-frontend and multipage-frontend) that are responsible for taking published content and displaying it on the site.
In turn, the publishing platform is itself composed of several apps. While we don't strictly build microservices, we do prefer to split services up into specific areas of responsibility.
The publishing-api is the main application in the platform. As the name implies, its primary task is to be the application programming interface (API) that the publishing apps talk to in order to publish their content. The apps talk to the API by sending JavaScript Object Notation (JSON), as described by the content schemas; in turn it sends content to the relevant content store, and also places it on a message queue for other interested content subscribers (eg email alerts and search indexing) to pick up.
As the platform has developed, the publishing-api has taken on more responsibilities. In addition to storing content, it has (or will soon have) the ability to:
- manage workflow - it currently supports draft creation/updates, publishing, unpublishling, and is expected to soon include functionality that will let content be sent for review and scheduling
- prepare content for use by frontends - it expands related links, and in the future will convert Govspeak (our markdown dialect used by editors) to HTML
- act as the main data source for some of our publishing apps - these apps have no database of their own, and use the API to present lists and details of documents to edit and publish.
The other main application is content-store. This has one responsibility, which is to answer the question "What content is at this URL?" It accepts JSON from the publishing-api and stores it locally for the frontend apps to request. Until recently it also carried out the link expansion functionality which is now being taken over by the publishing-api - you can read more about how we've improved content link updates in this post. Currently the content-store registers the paths for a piece of content with the router but this may also be moved to publishing-api in the future.
The final component of the platform is the router. This is actually two applications: the router itself, a very small Go app that keeps an in-memory map relating every route on the site to the frontend app that serves it; and the router-api, a Rails app that accepts route registrations from the rest of the publishing platform and triggers the router to reload them when necessary.
In fact there are two sets of routers and content-stores; one serves the live site, and one serves the draft site (the draft site lets publishing users preview content before publishing it). The publishing-api determines which content-store to send content to, depending on the document status; draft and live content go to the draft content-store, but only live content goes to the live content-store.
How it all fits together
The overall architecture looks like this:
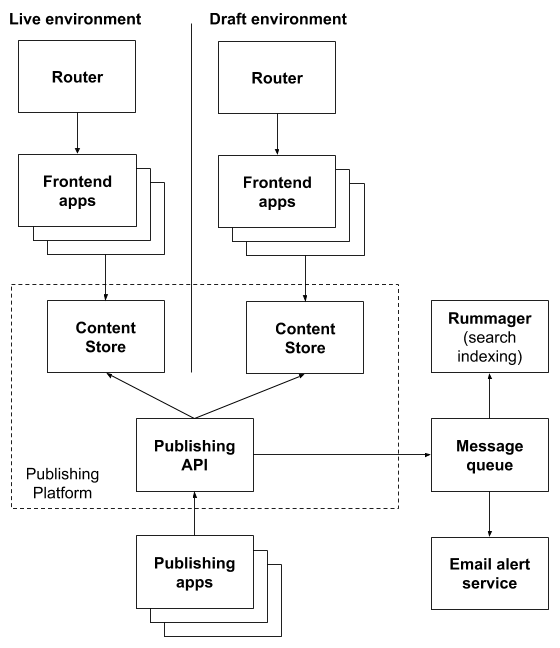
Most of this is already in place, but only a minority of content is using it. As the migration programme picks up speed, more and more of the pages on GOV.UK will be served via this simpler mechanism.
In addition, not all of the content served by the platform is currently using the message queue integration to manage search indexing and email alerting. We have some work to do on the reliability of the queue and its subscribing services, especially before we migrate critical email alerts like travel advice updates.
We'll keep updating you on the progress of this migration work with future blog posts.
If this sounds like a good place to work, take a look at Working for GDS - we're usually in search of talented people to come and join the team.
You can follow Daniel on Twitter, sign up now for email updates from this blog or subscribe to the feed.
