
The GDS Reliability Engineering team has implemented an alerting service to all teams using the open source software package Alertmanager. This helps GDS move towards the goal of using common monitoring tools across the department, which means teams use the same toolset and have better support.
At GDS we use Alertmanager, a tool that sends platform and application alerts to pre-configured:
- email addresses
- Slack channels
- paging software like Pagerduty
- ticketing systems like Zendesk
These alerts are based on metrics like CPU usage and memory smoke test failures generated by Prometheus, a metric service, or other tools. We also aggregate alerts into one notification and throttle these to avoid overwhelming team members with duplicated notifications.
The team decided to set up a centralised Alertmanager so we could manage alerts across GDS more effectively. We got this idea from Brian Brazil’s book ‘Prometheus: up & running’ and thought it would be helpful at GDS. We decided to host 3 Alertmanager instances to achieve a fault tolerant architecture. We came across a few technical challenges along the way, which we managed to solve with some creative workarounds.
Hosting Alertmanager
We implemented the Alertmanager cluster on ECS, the managed container service provided by Amazon Web Service (AWS). We did this instead of hosting our own container service as we wanted to avoid running, configuring and maintaining our own container orchestration software.
We then used the Fargate serverless infrastructure instead of EC2 virtual machines (VMs) as this combination helped us cut down on developer time needed to maintain infrastructure. In our case, this solution also helped us reduce infrastructure cost.
Technical problems implementing Alertmanager and our workarounds
When deploying software on your own dedicated hardware or VM, you have control on how to implement and configure the full technical stack of the software.
By choosing to deploy software on a managed service, we knew there would be a trade-off. On one hand we would get the benefit of not having to operate, maintain and manage part of the technical stack. On the other hand, we had to enter into a shared responsibility model with the service provider, and lost some configuration and implementation abilities required to run the software.
We found there was a mismatch of how Alertmanager is expected to be configured and used, with the configuration options available in ECS. We found some workarounds to solve the issues that we’d like to share.
Problem 1 - There was an issue related to the use of multiple ports
Alertmanager is implemented as a ‘task’ within an ECS service. We were using load balancers to discover tasks. However, the load balancers only support targeting a single task port. This created a problem for us as Alertmanager requires 2 ports to fully function. Alertmanager needs:
- one for Prometheus instances to communicate with the 3 Alertmanager instances and to provide the web user interface
- a second for mesh-networking between the instances to enable grouping, inhibition, and other functionalities
Without this workaround, Alertmanager would receive duplicated alerts from the 3 instances.
Solution
AWS ECS includes an integrated service discovery, which makes it possible for an ECS service to automatically register itself with a predictable and friendly DNS name in Route 53.
We created a DNS A record to each task running on ECS. This meant that when we started a new Alertmanager instance, it discovered the other tasks using each IP address in the A record so that the 3 instances of Alertmanager could communicate with each other. You can see our configuration code for more information.
Problem 2 - A configuration issue
ECS expected configuration data to be provided to containers in environment variables. This clashed with the way that Alertmanager read custom configuration from files. We needed a workaround for this otherwise we would not have been able to configure Alertmanager to do things like send information to Pagerduty.
Solution
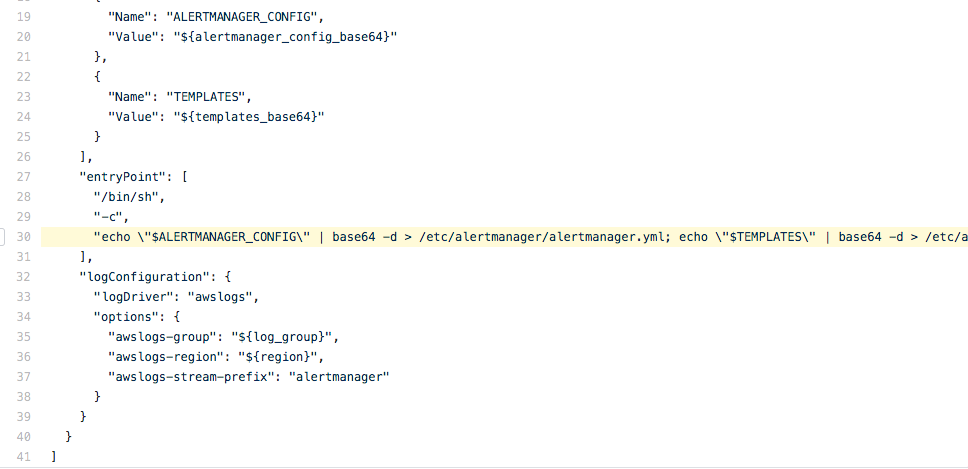
We used `--entrypoint` - a Docker parameter that lets commands run prior to launching Docker. We use this to launch a small shell script to grab Alertmanager configurations from the environment variables and put it in a file to be read by Alertmanager. You can see the configuration of the parameter in our source code.
What we’ve learned by using a managed container service
Our main reason for using a managed service was to reduce long-term maintenance costs and effort. We worked through multiple iterations before reaching our current implementation of Alertmanager and we learned some valuable lessons along the way.
Constraints with the managed service
We overcame a few hurdles to get Prometheus and Alertmanager up and running on the managed service as we found:
- it was not possible to attach the same persistent disk storage to the same container instances - this meant used VMs instead of ECS to host Prometheus
- a workaround was needed if you want more than one host ports for your container task
- a workaround was needed to run software to read files at startup on ECS
Although these limitations were specific to our implementation and the service provider we chose, we believe these are commons issues. If your organisation is looking to host software on different managed hosting services by other providers, a similar shared responsibility model will apply.
Failing fast helped us identify and solve problems quickly
It’s not always easy to choose the right tools, even with a lot of desk research.
We only found out the limitations of using the managed container service, when we started the implementation. There were a couple of reasons for this. We were not familiar with ECS and running a service discovery with ECS was not available at the time.
Our experience was a good example of the ‘fail fast, learn quickly’ principle in the Service Manual. Even though it took a few weeks of developer time to create workarounds, we were able to solve the issues and get the benefits of using the managed service.
We saved time and money by not using VMs
Using serverless infrastructure means we do not need to maintain VMs. This provides lots of benefits as we:
- do not need to reboot VM instances when there is a kernel upgrade
- do not need to worry about security patching for the VMs
- have reduced our infrastructure cost by 4 times by not using VMs as we only pay for resources we use
- have saved a significant amount in ongoing maintenance costs
Let us know if you’ve come across any other implementation problems and how you’ve worked around them in the comments.

2 comments
Comment by Alice Green posted on
Why did you choose to host it on ECS, rather than your own GOV.UK PaaS?
Or what about a managed Kubernetes service (like GKE). Kubernetes is an open standard, helping you to avoid lock-in to a particular provider.
Comment by Venus Bailey posted on
Hi Alice,
Alertmanager listens on multiple ports. At the time of implementation, GOV.UK PaaS did not natively support this kind of application. A recent feature on GOV.UK PaaS enables multiple ports via the use of network policies. Hosting a fully-functioning Alertmanager on PaaS is now possible.
GOV.UK PaaS is best suited for hosting 12-factor applications. In fact, we used GOV.UK PaaS to host Grafana, which was part of the visualisation aspect of the monitoring tools. At the time of implementation, we chose ECS because EKS, an Amazon managed Kubernetes service, was very new and using a brand new platform could be risky. We had used ECS in another GDS programme so we already had some in house expertise.
We would always look out for the most appropriate ways of running our applications and will consider using EKS or GOV.UK PaaS in the future.